

Les classements des modèles d’IA sont trompeurs
LMArena fait partie des classements les plus observés de l'écosystème, mais une étude montre que certains modèles d'IA trichent pour monter dans le classement

Bonjour tout le monde 👋
Le prochain webinar dédié aux formations Intelligence Artificielle d'Alyra va démarrer le 8 juillet à 18h !
📜Présentation des formateurs
🔍Le programme de chaque semaine
🔢Les chiffres clés de la formation
Ce sera le moment idéal pour vous renseigner et poser vos questions !
Au menu cette semaine
1️⃣Les actus de la semaine dans la blockchain et l'IA
2️⃣Sujet de la semaine : Les classement des modèles d’IA sont trompeurs
3️⃣Les dernières nouvelles d’Alyra
1️⃣Les actus de la semaine
Actus blockchain
👉Le Vietnam reconnaît officiellement les cryptos. Ce pays a voté une loi historique sur l'industrie des technologies numériques, qui entrera en vigueur le 1er janvier 2026. La loi classe les cryptomonnaies en quatre catégories : tokens de sécurité, tokens de paiement, tokens utilitaires et tokens mixtes. Au-delà de la régulation crypto, la loi prévoit des incitations fiscales pour les entreprises technologiques, notamment dans l'IA et les semi-conducteurs dans le but de positionner le Vietnam comme un acteur majeur du numérique à travers le monde.
👉Annonce de Morpho V2. La plateforme de prêts et d’emprunts Morpho a dévoilé sa deuxième version actuellement en développement qui apporterait plusieurs innovations. La première d’entre elles est Morpho Markets V2 qui permettrait entre autres les prêts et les emprunts à taux fixes avec des conditions flexibles, et une autre innovation serait Morpho Vaults V2 qui alloue automatiquement les actifs à travers différents marchés construits sur Morpho Blue pour que les prêteurs gagnent plus de rendements et les emprunteurs paient moins cher.
👉Paiements en stablecoins sur Shopify. La plateforme de commerce Shopify s’est associée avec le réseau de paiement Stripe et la blockchain Base pour pouvoir permettre à ses utilisateurs de payer en stablecoins USDC, et les marchands reçoivent les paiements dans leur devise locale sur leur compte bancaire classique. Ce service sera disponible pour les marchands Shopify dans 34 pays, et cette annonce coïncide avec l'introduction en bourse de Circle sur le NYSE et l'acquisition de Privy pour plus d’un milliard de dollars par Stripe.
👉L’armée américaine sponsorisée par Coinbase. La parade militaire commémorant le 250ème anniversaire de l’armée américaine a été sponsorisée par 22 entreprises et fondations. Certains sponsors ont été publiquement remerciés durant l'événement, notamment Coinbase, qui avait donné $1 million au comité d'investiture de Trump en janvier. Ces remerciements ont rapidement fait réagir sur les réseaux, mettant en évidence le fait que Coinbase refuse de s’impliquer dans des enjeux politiques, alors que cette sponsorisation montre le contraire.
Actus IA
👉Prévoir les tempêtes tropicales avec Google. Le géant technologique Google a lancé un nouveau site web appelé Weather Lab qui utilise le modèle d’IA Gencast pour prévoir les cyclones tropicaux. Ce système peut générer 50 scénarios différents pour la trajectoire, la taille et l'intensité d'une tempête jusqu'à 15 jours à l'avance. Selon Google, ses prédictions à cinq jours pour les trajectoires de cyclones dans l'Atlantique Nord et le Pacifique Est étaient en moyenne 140 km plus précises que celles du Centre européen de prévisions météo (ECMWF) en 2023-2024.
👉Meta attaque Crush AI en justice. Le géant technologique Meta a poursuivi le créateur d’une application d’IA nommée Crush AI qui générait des images dénudées. Crush AI évitait la modération en créant des dizaines de comptes publicitaires et en changeant fréquemment de noms de domaine. Selon des analyses, 90% du trafic de leurs sites provenait de Facebook ou Instagram, et Meta accuse l'entreprise d'avoir contourné ses processus de vérification pour diffuser plus de 8 000 publicités en deux semaines début 2025.
👉Violation des droits d’auteurs présumée chez Midjourney. Les sociétés Disney et Universal ont intenté une action en justice contre le générateur d’images Midjourney pour avoir entraîné ses modèles de génération et d'édition d'images sur leur contenu protégé sans autorisation. La plainte, déposée mercredi devant le tribunal fédéral de Californie, affirme que Midjourney a ignoré leurs demandes antérieures de cesser ces violations. Disney et Universal réclament un procès, mais il est également possible qu’un accord ou “settlement” soit trouvé.
👉Des groupes musicaux fictifs. L'industrie musicale fait face à l'explosion des "fake bands", des groupes fictifs créés par IA qui prolifèrent sur les plateformes de streaming comme Spotify ou Youtube. Le phénomène dépasse la simple expérimentation artistique pour devenir un modèle économique lucratif, où l’affaire Michael Smith a montré qu’il était possible de gagner des millions de dollars en créant des milliers de fausses chansons avec des bots. Chaque jour, plus de 20 000 nouveaux titres arrivent sur Spotify, dont une part croissante générée automatiquement.
2️⃣Le sujet de la semaine
Avec la multitude de modèles d’IA qui existent actuellement, nous sommes forcément amenés à comparer leurs performances pour savoir lequel utiliser. Pour savoir quel modèle est plus performant qu’un autre, il existe des classements comme LMArena qui sont fréquemment consultés pour comparer les modèles.
Cependant, une recherche réalisée par Cohere Labs a remis en question la fiabilité de ces classements (en particulier LMArena), notamment car certaines entreprises usent d’un certain nombre de méthodes pour que leurs modèles paraissent plus performants qu’ils ne le sont réellement.
Pour cette édition, nous allons présenter toutes les méthodes utilisées pour “tricher” dans les classements, et quelles sont les solutions pour y remédier.
Les moyens de tricher
Accès aux données disparate
Chatbot Arena a une politique non déclarée concernant l’accès à leurs données, qui est largement favorable aux modèles propriétaires. Ces derniers ont accès à beaucoup plus de données que les modèles Open Source/Weight, comme on peut le voir ci-dessous :
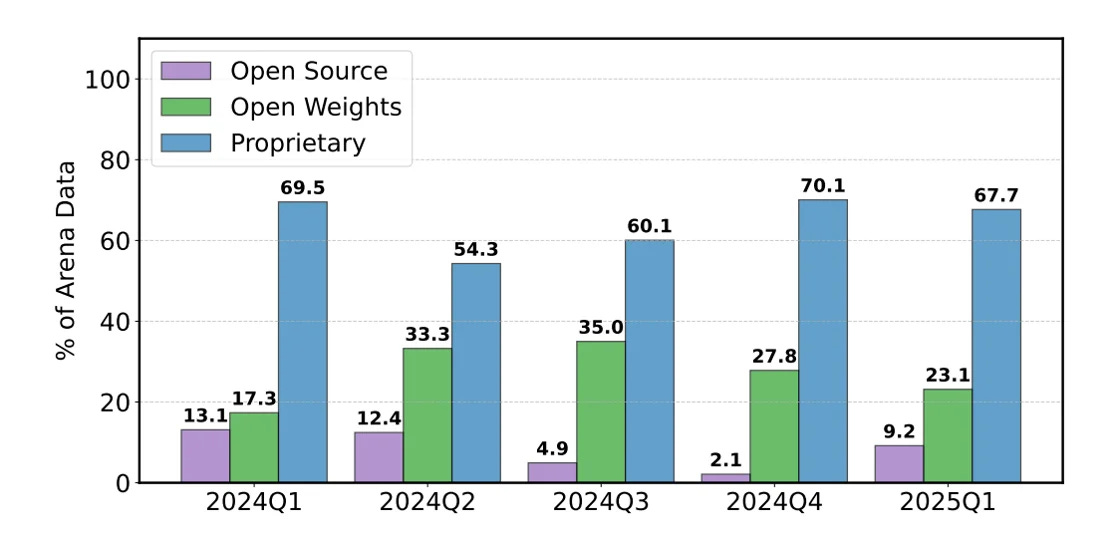
En tout, l’étude estime que plus de 60% des données totales de LMArena vont à quatre fournisseurs propriétaires (OpenAI, Google, Meta, Anthropic), tandis que tous les autres modèles ont accès aux 40% restants.
L’exemple le plus flagrant est la comparaison entre OpenAI qui a accès à 20.4% des données totales alors que 41 modèles Open Source ont collectivement accès à 8.9% de celles-ci.
La raison pour laquelle les modèles propriétaires ont accès à plus de données est purement économique. Les derniers modèles en date (en particulier les modèles de raisonnement) coûtent de plus en plus cher à évaluer, incitant LMArena et les fournisseurs de modèles à trouver des arrangements comme sponsoriser les coûts d'évaluation en échange d'un accès aux données.
Avoir accès à plus de données permet d’affiner davantage les modèles, ce qui fait que les modèles propriétaires partent déjà avec une longueur d’avance dans le classement.
Sélection des scores
Sur LMArena, il est possible de tester plusieurs variantes de modèles en privé. C’est une possibilité qui est la bienvenue lorsqu’on expérimente avec des modèles, cependant il n’y a aucune obligation de publier tous les résultats, ce qui incite les fournisseurs de modèles d’IA à tricher.
Par exemple, Meta a testé 27 variantes privées avant la sortie de Llama-4, et a retiré les scores des variantes testées en privé dans le but de conserver uniquement les meilleurs résultats.
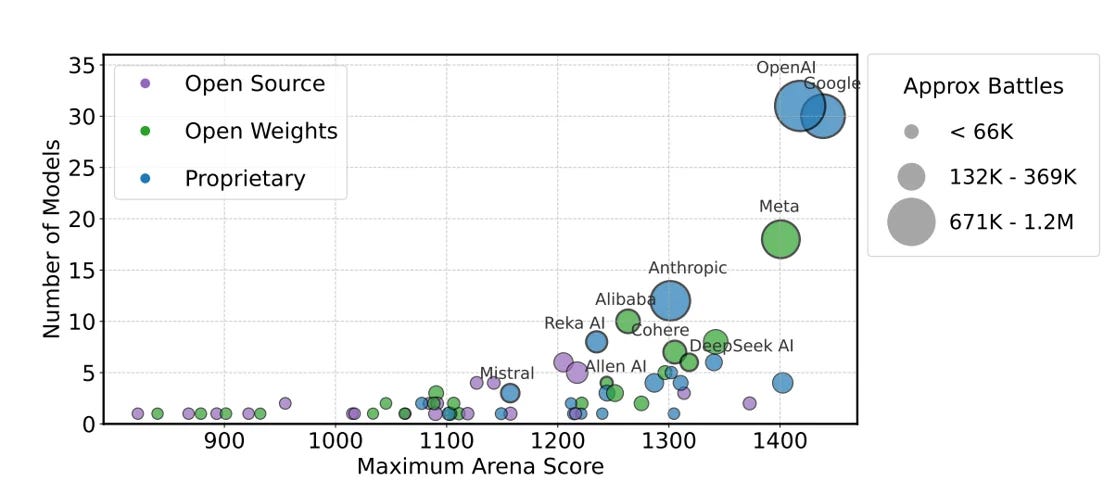
La recherche de Cohere Labs a montré l'existence d'une corrélation positive entre le nombre de variantes utilisées d’un modèle et ses performances. En testant 10 variantes, le score maximal augmente d’environ 100 points, et il augmente encore de 50 points en passant à 20 variantes.
Certains fournisseurs font donc exprès de soumettre un grand nombre de variantes pour suroptimiser leur score. D’une part, cela pénalise d’autres fournisseurs qui n’en soumettent qu’une seule (Reka, xAI…), et d’autre part nous devons prendre en compte le nombre de variantes utilisées en parallèle du score pour déterminer ses performances.
Ajustement excessif
Entre novembre 2024 et avril 2025, 20.14% des prompts étaient des duplicatas exacts ou quasi-identiques (jusqu'à 26.5% en mars 2025). Cette redondance offre un avantage pour tous les modèles qui ont été entraînés à partir des données de LMArena. C’est un peu comme s’il était possible d’obtenir les solutions à un examen en avance.
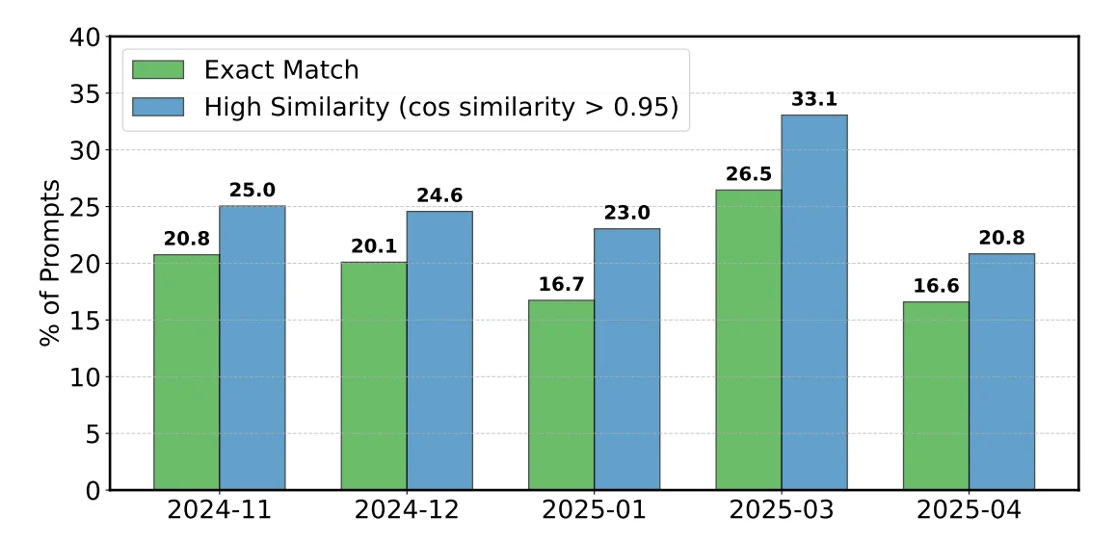
Quand bien même les données de LMArena évoluent de façon significative d’une année à l’autre, cette duplication laisse la possibilité aux modèles de surperformer, en particulier pour les modèles propriétaires qui possèdent l’accès le plus important aux données.
Les chercheurs ont entraîné trois variantes d'un modèle avec différentes proportions de données Arena (0%, 30%, 70%), et les résultats ont montré des gains substantiels :
0% de données provenant de LMArena : 23.5% de taux de victoire
30% de données : 42.7% (+81% de victoires)
70% de données : 49.9% (+112% de victoires)
Même avec une proportion réduite de données, le pourcentage de réussite augmente considérablement et ajoute un autre biais parmi la multitude qui a été mise en évidence par l’étude.
"Dépréciation silencieuse" des modèles
On dit qu’un modèle d’IA est “déprécié” lorsqu’il est mis en retrait par des fournisseurs. Cela peut être à cause de problèmes de performance, de sécurité, de coût ou pour l’arrivée d’une version supérieure. En général, ces événements sont annoncés par les fournisseurs.
Aujourd’hui, nous avons aussi ce qu’on appelle la “dépréciation silencieuse” où le modèle est progressivement retiré du service sans communication officielle aux utilisateurs. Il existe toujours officiellement, mais ne reçoit pratiquement plus aucune requête utilisateur.
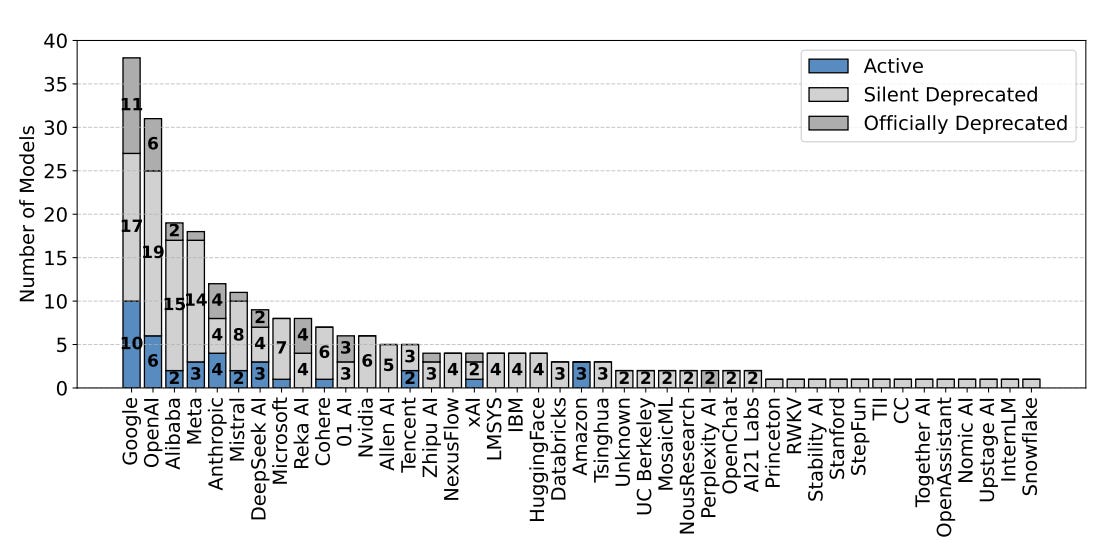
Sur 243 modèles publics, 205 ont été dépréciés silencieusement, en particuliers les modèles Open Weight/Source qui représentent environ 87% du lot.
LMArena suppose que les conditions d’évaluation sont constantes, mais si un modèle est déprécié, alors cette supposition fausse les résultats. Un modèle déprécié silencieusement reçoit beaucoup moins de requêtes que les autres pour s’améliorer, et cela impacte progressivement son classement puisqu’il n’est plus capable de s’entraîner sur les nouvelles données de LMArena.
Etant donné que les fournisseurs propriétaires ont très peu de modèles d’IA dépréciés, ils sont en meilleure capacité de rester haut dans le classement.
Avec toutes ces méthodes différentes pour fausser les performances réelles d’un modèle, il devient de plus en plus difficile de considérer les scores de LMArena comme des métriques pertinentes, surtout lorsqu’on constate qu’elles favorisent les modèles propriétaires…A croire que l’on cherche davantage à obtenir le score le plus haut possible au lieu de créer des modèles réellement performants.
Les solutions
A tous ces problèmes, les chercheurs ont proposé un certain nombre de solutions qui pourraient améliorer la pertinence de LMArena.
Interdiction de la rétractation des scores après soumission. Tous les résultats doivent être publiés de manière permanente, sans option de rétractation y compris pour les variantes privées. Il n'existe aucune justification scientifique raisonnable pour permettre à des acteurs de sélectionner les résultats en fonction de ce qui les arrange.
Établir des limites transparentes sur le nombre de modèles privés par fournisseur. Comme on a pu le voir, plus on utilise de variantes différentes et plus le score du modèle est élevé. Il est essentiel d'appliquer une limite stricte et publiquement divulguée (par exemple, maximum 3 variantes de modèles testées simultanément par fournisseur). Cela empêche les séries de tests excessives qui biaisent le classement tout en assurant une évaluation comparative équitable.
Assurer que les suppressions de modèles sont appliquées de manière égale. Les organisateurs de LMArena doivent supprimer une part égale entre les licences propriétaires, Open Weight et Open Source pour éviter de créer un accès asymétrique aux données qui désavantage les fournisseurs autres que propriétaires. Une politique raisonnable et transparente serait de déprécier le 30ème percentile inférieur pour chaque groupe de modèles.
Mettre en œuvre un échantillonnage équitable. Les taux d'échantillonnage (requêtes des utilisateurs) quotidien maximum de modèles d'OpenAI ou Google vont jusqu'à 34%, ce qui est 10 fois plus que ce qui est observé chez d’autres fournisseurs comme Allen AI. Une solution serait de revenir à une méthode d'échantillonnage actif proposée par les organisateurs eux-mêmes pour prioriser les autres modèles.
Transparence sur les modèles qui sont supprimés du classement. Pour s'assurer que la politique de dépréciation est mise en œuvre équitablement, il est important qu'il y ait une liste complète de quels modèles ont été supprimés du classement, y compris les dépréciations silencieuses.
Avec ces solutions, LMArena peut devenir un outil bien plus pertinent pour comparer la performance des modèles entre eux.
Se former à l'IA avec Alyra
LMArena fait partie des systèmes d’évaluation les plus observés de l’écosystème, et nous-mêmes avons souvent utilisé LMArena dans le cadre de cette newsletter comme outil de mesure pour estimer la performance des modèles d’IA.
Mais suite à la publication de cette étude (dont la version complète se trouve ici), on réalise que les mesures de LMArena sont devenues un objectif à atteindre, en particulier pour les modèles propriétaires qui cherchent à optimiser leurs scores. Et lorsqu’une mesure devient une cible, ce n’est plus une bonne mesure.
En conséquence, il est devenu nécessaire d’utiliser d’autres évaluations pour estimer les performances réelles d’un modèle, et cela fait partie des tâches à réaliser en tant que professionnel de l’IA. La veille informationnelle et l’adoption de nouveaux outils sont nécessaires en tant que professionnel, et cela fait partie des compétences que l’on enseigne chez Alyra.
Si ces compétences vous intéressent, Alyra vous propose de vous y former !

85% des métiers de 2030 n'existent pas encore, c'est ce que révèle une étude mise en avant par France Travail.
Ainsi, nous vous proposons des formations qui vous permettront d'acquérir des compétences concrètes et reconnues pour vous préparer aux opportunités de demain !
✅ Les plus grands experts de l'écosystème
✅ Un réseau de 2500+ alumni et 150+ partenaires professionnels
✅ Allier théorie et pratique pour vous permettre de concevoir vos propres projets.
✅ Des certifications uniques reconnues par l'État
✅ +70% des cours en live avec un formateur
Développement IA
Du point de vue des développeurs , toutes les chances sont réunies pour que l'IA devienne l'interface de demain avec le web. Contrôler les IA reviendra donc à contrôler l'accès au web.
Si vous êtes passionné par les nouvelles technologies, plus particulièrement à l’IA et que :
Vous avez un intérêt marqué pour les algorithmes et les systèmes d'apprentissage automatique.
Vous possédez des compétences en programmation, notamment en langages comme Python.
Vous êtes curieux de comprendre comment les machines apprennent et prennent des décisions.
Vous souhaitez appliquer des solutions d'IA à des problèmes réels dans divers secteurs tels que la finance, la santé, ou le commerce.
Vous cherchez à utiliser l’IA de façon innovante
Alors la formation “Développement IA” d’Alyra est faite pour vous !
Consulting IA
Il s’agit d'un programme pour les professionnels, les entrepreneurs, les personnes en quête de reconversion et les passionnés, conçu de façon à engranger toutes les connaissances et aiguiser toutes les compétences nécessaires à la valorisation de ces technologies porteuses.
Si vous êtes passionné par les nouvelles technologies, plus particulièrement à l’IA et que :
Vous voulez comprendre et savoir expliquer les mécanismes de l’IA
Vous cherchez à maîtriser votre utilisation de l’IA, en passant par les outils avancés et les plugins
Vous souhaitez mettre en place une stratégie de transformation digitale avec l’IA dans un projet ou une entreprise
Vous voulez vous informer sur les défis actuels de l’IA, et ses perspectives futures
Alors la formation “Consulting IA” d’Alyra est faite pour vous !
3️⃣Dernières nouvelles d’Alyra

Un nouvel épisode des chroniques d'Alyra aura lieu ce jeudi à 12h30 avec nos chroniqueurs habituels !
Au programme :
⛓️Les actus blockchain de la semaine
🪙Les stratégies DeFi de Pascal
🤖Les actus sur l'intelligence artificielle
🔍Un sujet de fond
Cela se passera en direct sur la chaîne Twitch et le compte Twitter/X de l'école !
Merci à toutes et à tous, rendez-vous mercredi prochain ! 👋
Avez-vous apprécié ce contenu ? N’hésitez pas à en parler sur les réseaux sociaux et à nous suivre ❤️